

「想像力は無限ですが、それを形にするのはなかなか難しい」—これが、多くのクリエイターが直面する課題です。
しかしもしテキスト一つであなたの想像を現実に変えることができるとしたら?ここで紹介するDALL-Eは、まさにそのような夢のような技術です。
この記事では、初心者のためにDALL-Eを使って驚くべき画像を作成する方法を詳しく解説します。創造性を新たな次元へと導くこの革新的なツールの可能性を、一緒に探ってみましょう。
DALL-Eとは何か?
DALL-EはOpenAIによって開発された画像生成AIです。テキストのプロンプトを基にして、存在しない画像を生成することができます。この技術はクリエイティブな分野で画期的な変革をもたらしています。
プロンプトとはChatGPTなどのAIへ命令する単語や文章の事を言います。
例えばこんな物が作れます
まずどのような画像が生成できるのかイメージしにくいと思うのでいくつか例を見てみましょう。
かなりシンプルなプロンプトですが、違和感のないイラストが完成しました。

次にリアルな人物を生成してもらおうとすると、具体的な特徴を逆に質問してもらうことでさらにイメージ通りの画像が生成されました。
この聞き返す質問であったり、会話形式である点がMidjourneyなどの他の生成AIでの画像生成と大きく違う点です。初心者にとってはイメージ通りの画像生成のために特にこの会話形式が役に立つでしょう。
生成した画像の保存方法
初めてDALL-Eで画像生成を行った方はこの生成した画像をどのように保存すればいいか分からない人もいると思います。
保存方法は簡単で画像をクリックした後右上のダウンロードボタンをクリックし、保存したい場所を指定し名前を付けて保存するだけです。

DALL-Eを使う下準備
現在DALL-EはOpenAIによって作られたカスタムGPT(GPTs)の1つとして利用可能になっています。
なのでまずはカスタムGPT(GPTs)を使えるようにする必要があります。カスタムGPT(GPTs)自体の使い方はもうわかっているという方はこのセクションは飛ばしてかまいません。
ChatGPT Plus (有料プラン)へ登録する : 月額20ドル(約3000円)
OpenAIのChatGPT公式サイトへアクセス
アカウントを持っていない人はサインアップを、持っている人はログインを行ってください。
ログインが完了すると左上のChatGPTという場所をクリックしてUpgrade to Plusへ進みます。
そして決済登録を完了すると有料プランへの加入が完了し、左側にExploreという文字が追加されます。
使いたいカスタムGPT(GPTs)を選択する
左上のExploreをクリックしてGPTsの作成などが出来る画面へ移動します。
クリックすると下のような画面になります。今回はDALL-Eを使用するので中央の「DALL-E」という部分をクリックしてください。
下の画面が表示されていればDALL-Eを使用する準備は完了です。
基本的なDALL-Eの使い方
基本的な使い方に関しては下のプロンプト入力欄に生成してほしい画像の内容を入力するだけで大丈夫です。
しかし、こういう物が作りたいというイメージ通りの画像を生成するためにはそのプロンプトを工夫する必要があります。
ここでは作成例といっしょにプロンプトを紹介し、プロンプトに対しての考え方に触れていただきたいと思います。
プロンプトを英語で書くメリット
プロンプト自体は日本語でも英語でも構いませんが、できれば単語のみでも英語で記述すると様々なメリットがあります。(日本語と英語の混在はNG)
- 広い互換性と正確な回答のため
- 英語のプロンプトを使うと、AIモデルと上手く連携できます。なぜなら、多くのAIは英語で学習しているからです。英語は世界中でよく使われる言語なのでAIも英語をよく理解します。これにより英語で入力するとAIが正確に理解しやすくなり、期待通りの答えが得られる可能性が高まります。
- 豊富なリソースへのアクセス
- 英語でプロンプトを作ると、英語の教材やツールに簡単にアクセスできます。科学や技術の分野では特に、たくさんの資料やガイドが英語で提供されています。これらを使えば、プロンプトの作り方や結果の解釈がもっと簡単になり勘違いのような間違いを防ぐことにもつながります。
- 最新のAI技術を活用できる
- AIの世界は日々進化していて、新しいモデルや方法が次々に出てきます。これらの新しい技術は、大抵最初に英語で発表されます。英語のプロンプトを使えばこれら最新の技術をすぐに使うことができます。
- トークンの節約
- AIモデルは入力されたテキストを「トークン」という単位に分けて処理します。テキスト生成AIでは、これらのトークンの数には限りがあります。英語は日本語など他の言語と比べて、トークンの数が少なくなる傾向があります。これは英語が単語ごとに空白で区切られているためです。英語でプロンプトを作ると同じ情報を伝えるのに必要なトークン数が減り、より長い内容をAIに入力できるようになります。
このように英語のプロンプトを使うとAIとの連携がスムーズになり、最新技術の活用や効率的な情報伝達が可能になります。
少しでも英語が分かる場合や、作ってもらいたい物が詳細に決まっている場合は是非英語でのプロンプト作成にチャレンジしてみてください。
明確に作りたいものは決まっていないがジャンルは決まっている
画像を生成したいとき、なんとなくこういう物を作ってほしいけど細かく決めているわけではない。そんなシチュエーションも存在すると思います。
その場合例えば「かわいい犬のオリジナルキャラクター」という風にそのジャンルのみプロンプトとして入力することでランダム生成することが出来ます。

この生成結果で満足したならこれを保存し利用しても良いですし、この画像よりもっとリアルなものがいいという場合は「もっとリアルめで」などとさらに追加でプロンプトを入力することでこの画像の配置やカラーリングなどを残したまま修正を加えてくれます。

作りたい物が決まっている場合
作りたい物が明確な場合はいかにChatGPTに誤解されず詳細に伝えるかがカギになります。
先ほど「かわいい犬のオリジナルキャラクター」を作りましたが、今回は明確に「スーツを着てメガネをかけている賢そうなゴールデンレトリバーのキャラクターが本を読んでいる」というシチュエーションの画像が作りたいとしましょう。

どうでしょうか、先ほどの「かわいい犬のオリジナルキャラクター」とは打って変わってイメージするものにより近い画像が生成されました。
ここまでのまとめ
ここまで本当に基本中の基本の使い方を紹介してきました。ちょっとDALL-Eを触って画像生成がどんなものか見たい場合はこれで十分だと思いますが、DALL-Eを使いこなすためには様々なテクニックがあります。
ここからは応用編としてDALL-Eをさらに活用するためのテクニックを紹介していきます。
さらにDALL-Eを活用するための応用テクニック
まずDALL-Eの仕組みを理解する
DALL-Eと素のChatGPTとの一番大きな違いはプロンプトを入力した時の動作になります。
ChatGPTでは入力された内容をそのまま理解し命令に従いますが、DALL-Eの場合一旦ChatGPTが入力されたプロンプトを読み取り、その意図を汲む形で画像生成に適したプロンプトを作成し直しそれをDALL-Eに送信しています。
つまりDALL-Eに直接命令しているわけではなくChatGPTが詳細な画像生成に適したプロンプトの作成を肩代わりしてくれているというわけです。
どういうプロンプトがDALL-Eへ入力されたのか見てみる
では実際どのようなプロンプトがChatGPTからDALL-Eへ送信されているのか見てみましょう。
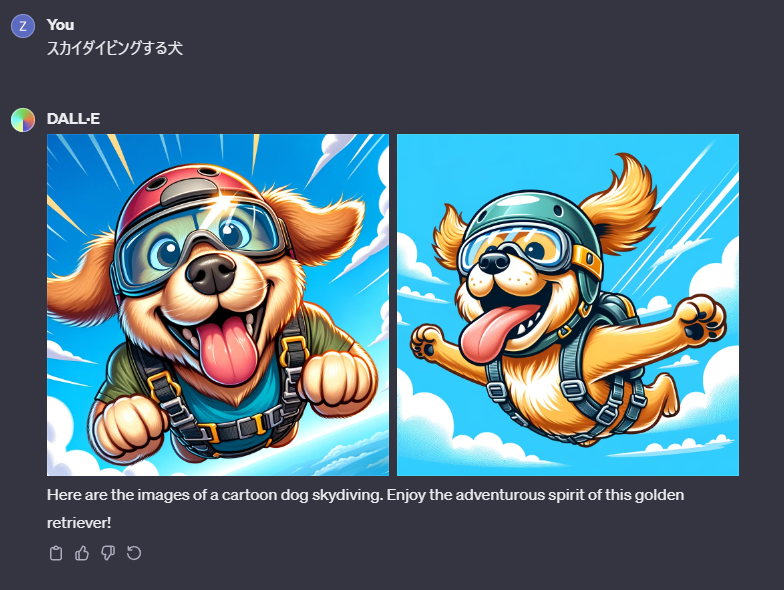
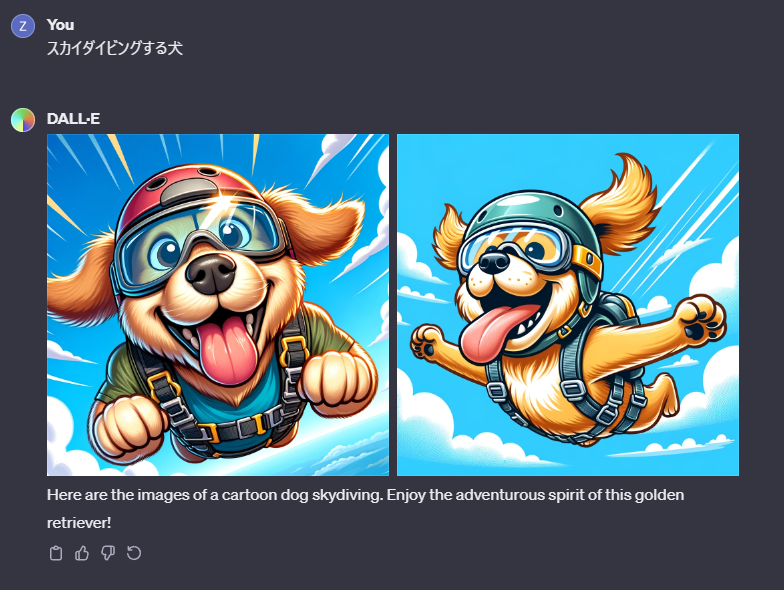
この左の画像についてプロンプトを確認してみたいと思います。左の画像をまずクリックして

右上のこの赤丸の部分をクリックしてください。
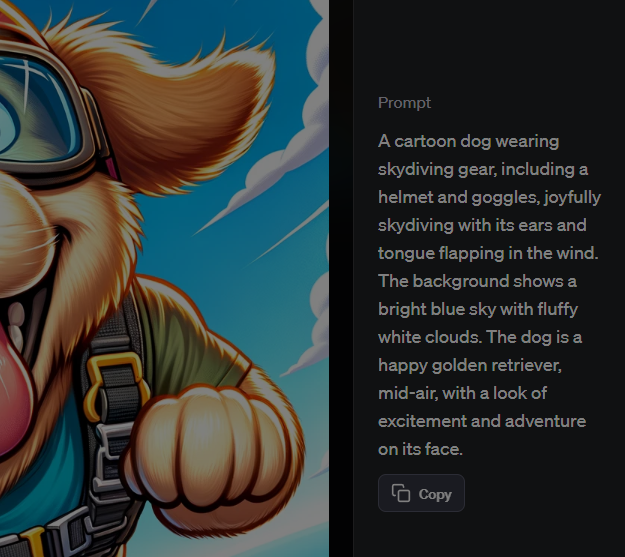
そうするとこのような画面が表示されると思います。
このPrompt と書かれている下の部分が実際にChatGPTからDALL-Eへ送信されたプロンプトです。
「スカイダイビングする犬」という私の入力したプロンプトが下のプロンプトへ変換されていました。
A cartoon dog wearing skydiving gear, including a helmet and goggles, joyfully skydiving with its ears and tongue flapping in the wind. The background shows a bright blue sky with fluffy white clouds. The dog is a happy golden retriever, mid-air, with a look of excitement and adventure on its face.
漫画の犬がスカイダイビングの装備、ヘルメットとゴーグルを身につけて、耳と舌を風になびかせながら喜びに満ちてスカイダイビングをしています。背景は明るい青空とふわふわの白い雲が描かれています。犬はハッピーなゴールデンレトリバーで、空中にいて、顔には冒険と興奮の表情が浮かんでいます。
「スカイダイビングする犬」としか入力していなかったプロンプトをChatGPTがこのプロンプトのように解釈した上でDALL-Eへ送信してくれていたようです。
この英語のプロンプトの特徴を見てみると、画像の特徴になる部分が分かりやすいようにカンマ(,)で区切られているのが分かります。実際生成AIへのプロンプトではこのように入力したい内容の特性をカンマで区切ることによって箇条書きのように分かりやすく入力することが有効とされています。
過去の上手くいったプロンプトを再活用する
例えば先ほどの画像のテイストが気に入った場合に、今度は犬ではなく猫で同じような画像が生成したい場合について考えてみましょう。
その場合「スカイダイビングする猫」とすると
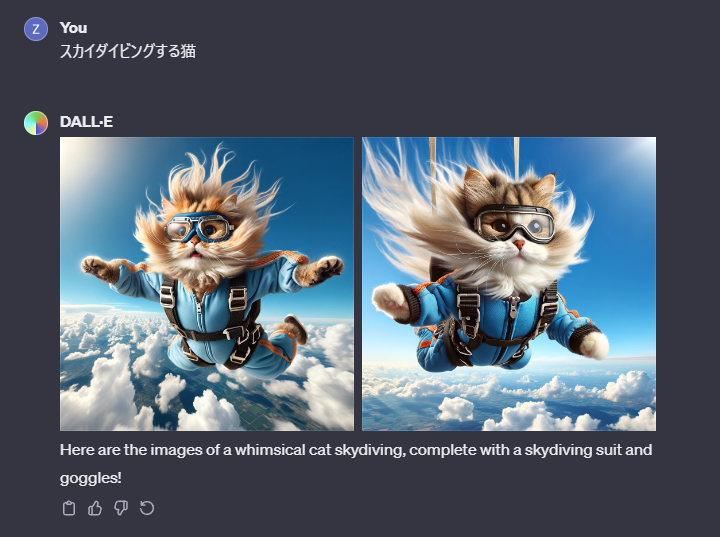
上のように先ほどの雰囲気とは違ったものが生成されました。
左の画像のプロンプトを確認してみるとやはり先ほどとは違ったプロンプトがChatGPTからDALL-Eへ送信されていたようです。
A whimsical image of a cat skydiving. The cat is wearing a miniature skydiving suit and goggles, with its fur fluffed up in the wind. The background shows a bright blue sky dotted with fluffy white clouds. The cat has an expression of thrill and excitement, its paws outstretched as if embracing the wind. The scene is playful and light-hearted, capturing the surreal and amusing idea of a cat engaging in an extreme sport.
空中でスカイダイビングをする猫のユーモラスなイメージです。猫はミニチュアのスカイダイビングスーツとゴーグルを身につけ、風に毛がふわふわとなっています。背景には明るい青空が広がり、ふわふわの白い雲が点在しています。猫はスリルと興奮の表情を浮かべ、風を抱きしめるかのように前足を伸ばしています。このシーンは遊び心があり、軽快で、極端なスポーツに挑戦する猫というシュールで面白いアイデアを捉えています。
つまり細かく指定しないシンプルなプロンプトを入力した場合ChatGPTがオリジナルでその状況を付け加えてDALL-Eへ送信するため同じようなイメージ・構図の物を量産するのには一工夫必要になります。
「スカイダイビングする犬」のプロンプトを再度見てみましょう。
A cartoon dog wearing skydiving gear, including a helmet and goggles, joyfully skydiving with its ears and tongue flapping in the wind. The background shows a bright blue sky with fluffy white clouds. The dog is a happy golden retriever, mid-air, with a look of excitement and adventure on its face.
この中で「犬」の部分を「猫」に変えるとその他のイメージは同じまま犬が猫に変わったものが生成されるはずです。
A cartoon cat wearing skydiving gear, including a helmet and goggles, joyfully skydiving with its ears and tongue flapping in the wind. The background shows a bright blue sky with fluffy white clouds. The cat is a happy, mid-air, with a look of excitement and adventure on its face.
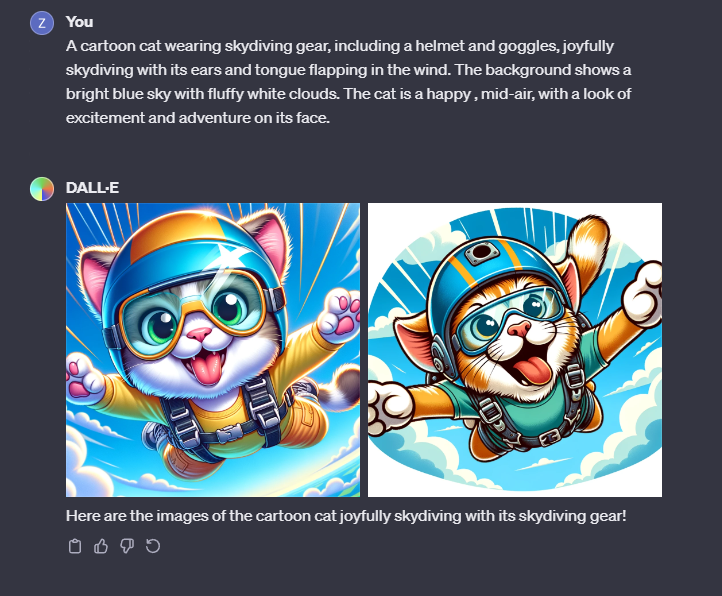
どうでしょうか、かなり最初の「スカイダイビングする犬」で生成したものに近く犬が猫に変更された画像が生成できたと思います。
ちなみにこの画像を生成するためにDALL-Eへ送信されたプロンプトは下のようになっています。ここから分かるのは使用したプロンプトをそのまま利用するのではなくやはり私が入力したプロンプトを元にさらに詳細な情報になるようにChatGPTがプロンプトを付け加えた上で送信しています。
A cartoon image of a joyful cat skydiving, wearing skydiving gear including a helmet and goggles. The cat’s ears and tongue are flapping in the wind, adding to the playful nature of the scene. The background features a bright blue sky with fluffy white clouds, enhancing the feeling of being high in the air. The cat is depicted in mid-air, with its limbs spread out, showcasing a look of excitement and adventure on its face. The image is colorful, vibrant, and captures the cat’s happiness and thrill of skydiving.
このように自分のイメージ通りに生成できた画像のプロンプトを確認し、変更したい点のみを修正したうえで再度DALL-Eへ入力する。という流れが自分の思った画像を生成するための1つのテクニックになります。
ChatGPTの生成するプロンプトの内容を詳しく見てみる
先ほど私たちが入力したプロンプトを元にChatGPTが修正を加えてDALL-Eへ送信していることを紹介しました。
ではそのChatGPTの生成するプロンプトにはどのような特徴があるのか見てみましょう。
A cartoon image of a joyful cat skydiving, wearing skydiving gear including a helmet and goggles. The cat’s ears and tongue are flapping in the wind, adding to the playful nature of the scene. The background features a bright blue sky with fluffy white clouds, enhancing the feeling of being high in the air. The cat is depicted in mid-air, with its limbs spread out, showcasing a look of excitement and adventure on its face. The image is colorful, vibrant, and captures the cat’s happiness and thrill of skydiving.
例えば先ほどの「スカイダイビングする猫」として生成したプロンプトを見てみます。
この画像生成のためのプロンプトを「主題」「環境」「アクション」に分類して解説すると以下のようになります。
- 主題 (Subject):
- “A cartoon image of a joyful cat” – これは画像の主要な被写体を指しています。ここでの主題は「漫画風の楽しそうな猫」です。
- 環境(Setting):
- “The background features a bright blue sky with fluffy white clouds” – これは画像の背景を説明しています。背景は「明るい青い空とふわふわの白い雲」で、高い空中にいる感じを強調しています。
- アクション(Action):
- “skydiving, wearing skydiving gear including a helmet and goggles” – これは猫がしている行動とその装備を説明しています。アクションは「スカイダイビングをしていて、ヘルメットとゴーグルを含むスカイダイビングの装備を着用している」です。
- “The cat’s ears and tongue are flapping in the wind” – これもアクションの一部で、動きの詳細を加えています。猫の耳と舌が風ではためいている様子が描かれています。
- “The cat is depicted in mid-air, with its limbs spread out” – これは猫の具体的なポーズを説明しており、スカイダイビング中の動きを表しています。
- 感情・雰囲気(Emotion/Expression):
- “showcasing a look of excitement and adventure on its face” – これは猫の表情に関する説明で、画像全体の感情や雰囲気を設定しています。猫の顔には「興奮と冒険の表情」が見られます。
- “The image is colorful, vibrant” – これは画像の全体的なスタイルと雰囲気を示しており、「カラフルで活気に満ちた」様子を表しています。
このプロンプトには存在しませんでしたが他にも
5. 具体的な物体(Objects): シーン内の具体的な物体。例えば, キャットニップのガーニッシュ, チキンのピース, サーモンパテ, 魚フレークなど。
6. 画風(Artistic style):絵の描き方や表現方法の特徴です。別の章でも詳細に説明しますが詳細にプロンプトすることで自由な自分の描きたい絵の表現能が飛躍的に上がります。技法 (Technique), 素材 (Medium), 時代・流派 (Historical Period/Art Movement), 構成・視点 (Composition & Perspective) に分類して定義します。
の6つの項目に分かれています。よって自身の生成したい画像の特徴をこの6個のカテゴリに当てはめたうえでプロンプトを生成すればより精度の高いものが作成できることが分かります。
自身の画像を元に生成も可能
プロンプトに関する仕組みや考え方をここまでは話してきましたが、見本がある場合より直感的に自分のイメージに近いものを作成する方法があります。
それは直接その見本となる画像をアップロードし、修正してほしい点を伝えることです。

上の例では画像の犬を猫に変更してもらいました。細かく見ると角度など少々違う部分もありますが大枠としてはイメージ通りに犬を猫に変更することができました。
しかしなぜこのようにアングルや周りの環境などに誤差が生じるのかと言うと、この画像の修正方法は実際に画像を修正しているのではなくこの画像を読み取ったうえで新たにプロンプトを作成し1から生成していることが大きな理由です。
この手法を使えばインターネット上にある画像を元にそれに近い画像を生成することも可能になります。
このようにDALL-EとChatGPT、そしてプロンプトの構造を理解することによってさらに画像生成の幅は広がることでしょう。
DALL-Eによる画像生成の実例とインスピレーション
ここからは実際に様々なカテゴリの画像を生成した結果を見ることでどのような物をDALL-Eで生成するのかの参考にして下さい。
DALL-Eでの画像生成のカテゴリとして得意不得意を100点満点で聞いた結果は以下です。
- アートとイラストレーション(85/100): DALL-Eは特にアートやイラストレーションの生成に優れています。創造的でユニークな画像を生成する能力が高く、多様なスタイルやテーマに対応できます。
- リアリスティックな風景(75/100): 自然の風景や都市の景観など、リアリスティックな画像の生成も得意ですが、細部の正確さや一貫性においてはまだ改善の余地があります。
- ポートレートと人物画(70/100): 人物のポートレートや顔の表現は比較的うまく生成できますが、顔の細部や表情の自然さにはばらつきがあります。
- 動物と生物(80/100): 動物やその他の生物の画像は、比較的リアリスティックに生成できることが多いですが、稀に解剖学的な正確さに欠けることがあります。
- 抽象的なアート(90/100): 抽象的なアートやパターンの生成には特に優れており、創造的でユニークな作品を生み出すことができます。
- 科学的・技術的図解(65/100): 科学的な概念や技術的な図解を生成する場合、正確さや細部の表現に課題が残ります。
- 食べ物と料理(80/100): 食べ物や料理の画像は比較的リアリスティックに生成できますが、時には不自然な色合いや構成になることがあります。
- ファッションと衣服(75/100): ファッションアイテムや衣服のデザインは創造的に生成できますが、実際の衣服の質感やドレープを完璧に再現するのは難しい場合があります。
本の表紙や映画のポスター
アートとイラストレーション(85/100): DALL-Eは特にアートやイラストレーションの生成に優れています。創造的でユニークな画像を生成する能力が高く、多様なスタイルやテーマに対応できます。
アートやイラストの代表例である本の表紙やポスターに関してはかなり高精度での生成が可能なようです。
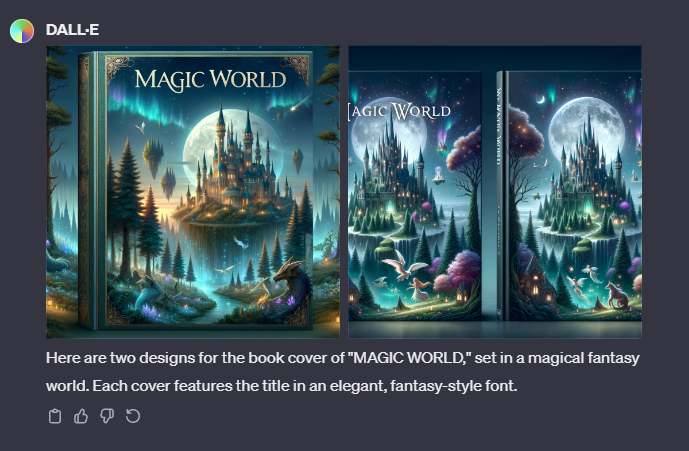
実際に生成してみると確かに違和感のない物が出来上がりました。
DALL-E以外の他の生成AIが不得意とする文字の生成もうまくいっている点には驚きです。

今度は某ター〇ネーターをイメージした映画のポスターを作ってもらいました。先ほどと同様違和感なく生成できており文字に関してもうまく生成できています。
自然の風景や建造物
リアリスティックな風景(75/100): 自然の風景や都市の景観など、リアリスティックな画像の生成も得意ですが、細部の正確さや一貫性においてはまだ改善の余地があります。

日本の原風景をより出来るだけ実写に近く表現してもらいました。その画像自体は良く出来ている一方実写に寄せるのはここが限界のようです。現実と見間違えるというレベルではありませんがリアル調のイラスト・アートとしては良く出来ています。

実在する歴史的建造物である「ベルサイユ宮殿」を作成してもらいました。DALL-Eは現実に存在するものやアーティストの画風など幅広く知識として持っているためこのような実在するものに対しての生成は特に得意なようです。
人物
ポートレートと人物画(70/100): 人物のポートレートや顔の表現は比較的うまく生成できますが、顔の細部や表情の自然さにはばらつきがあります。
動物など生物全般
動物と生物(80/100): 動物やその他の生物の画像は、比較的リアリスティックに生成できることが多いですが、稀に解剖学的な正確さに欠けることがあります。
抽象的なアート
抽象的なアート(90/100): 抽象的なアートやパターンの生成には特に優れており、創造的でユニークな作品を生み出すことができます。
科学技術の図
科学的・技術的図解(65/100): 科学的な概念や技術的な図解を生成する場合、正確さや細部の表現に課題が残ります。
食べ物と料理
食べ物と料理(80/100): 食べ物や料理の画像は比較的リアリスティックに生成できますが、時には不自然な色合いや構成になることがあります。
衣服やファッションアイテム
ファッションと衣服(75/100): ファッションアイテムや衣服のデザインは創造的に生成できますが、実際の衣服の質感やドレープを完璧に再現するのは難しい場合があります。
まとめ
DALL-Eは私たちの創造性を新たな次元に引き上げるツールです。
デザイン関係の仕事をしている方に限らず様々な創作を行う人にとって有効なツールであることは間違いないでしょう。この記事を通じてDALL-Eの基本を学び、自分だけの素晴らしい作品を生み出していきましょう。







